1. Metadata
IRI |
|
Title |
Loc-I Supermodel Specifciation |
Description |
This Model - the Loc-I Supermodel - is the Location Index (Loc-I) Projects's overarching data model that provides integration logic for all Loc-I elements. It is based on the general-purpose Supermodel Model. |
Created |
2022-02-24 |
Modified |
2022-03-30 |
Issued |
0000-00-00 |
Creator |
|
Publisher |
|
License |
|
Machine-readable form |
2. Preamble
2.1. Abstract
This Model - the Loc-I Supermodel - is the Location Index (Loc-I) Project's overarching data model that provides integration logic for all Loc-I elements. It is based on the general-purpose Supermodel Model.
2.2. Namespaces
This model is built on a "baseline" of Semantic Web models which use a variatey of namespaces. Prefixes for these namespaces, used througout this document, are listed below.
| Prefix | Namespace | Description |
|---|---|---|
|
the Supermodel meta-model |
|
|
Dublin Core Terms vocabulary namespace |
|
|
Generic examples namespace |
|
|
LocI Ontology - original LocI Project 2018 ontology |
|
|
Web Ontology Language ontology namespace |
|
|
RDF Schema ontology namespace |
|
|
Supermodel Terms & Definitions Vocabulary |
|
|
Sensor, Observation, Sample, and Actuator ontology namespace |
|
|
Simple Knowledge Organization System (SKOS) ontology namespace |
|
|
Time Ontology in OWL namespace |
|
|
Vocabulary of Interlinked Data (VoID) ontology namespace |
|
|
XML Schema Definitions ontology namespace |
2.3. Terms & Definitions
The following terms appear in this document and, when they do, the definitions in this section apply to them.
These terms are presented as a formal Semantic Web vocabulary at
- Central Class
-
Central Classes are the generic data classes at the centre of Data Domains with high-level relationships between them defined in this supermodel.
These classes are taken from general standards - usually well-known international standards - and specialised and extended within implementation scenarios to cater for specific needs.
- Data Domain
-
High-level conceptual areas within which Geosicence Australia has data.
These Data Domains are not themed scientificly - 'geology', 'hydrogeology', etc. - but instead based on parts of the Observations & Measurement [ISO19156] standard, realised in Semantic Web form in the SOSA Ontology, part of the Semantic Sensor Network Ontology [SSN].
Current Data Domain are shown in Figure 1.
- Knowledge Graph
-
A Knowledge Graph is a dataset that uses a graph data tructure - nodes and edges - with strongly-defined elements.
- Linked Data
-
A set of technologies and conventions defined by the World Wide Web Consortium that aim to present data in both human- and machine-readable form over the Internet.
Linked Data is strongly-defined with each element having either a local definition or a link to an available definition on the Internet.
Linked Data is graph-based in nature, that is it consistes of nodes and edges that can forever be linked to further conceps with defined relationships.
- Location Index
-
A project aiming to provide a consistent way to seamlessly integrate spatial data from distributed sources.
- Ontology
-
In computer science and information science, an ontology encompasses a representation, formal naming, and definition of the categories, properties, and relations between the concepts, data, and entities that substantiate one, many, or all domains of discourse.
The word ontology was originally defined as "the branch of philosophy that studies concepts such as existence, being, becoming, and reality". and the computer science term is derived from that definition.
- Semantic Web
-
The World Wide Web Consortium's vision of an Internet-based web of Linked Data.
Semantic Web is used to refer to something more than just the technologies and conventions of Linked Data; the term also encompases a specific set of interoperable data models - often called ontologies - published by the W3C, other standards bodies and some well-known companies.
The 'semantic' refers to the strongly-defined nature of the elements in the Semantic Web: the meaning of Semantic Web data is as precicely defined as any data can be.
2.4. Conventions
All model diagrams use elements introduced in Figure 1. These elements are defined in the RDF, RDFS and OWL ontologies, see [OWL] for mode details.
All code snippets in this document, used to show formal and machine-readable versions of concepts, are expressed using the Turtle RDF syntax [TTL].
3. Introduction
3.1. Loc-I Project
The Location Index (LOC-I) project, established in 2018, created a methodology and data models framework providing for a consistent way to seamlessly integrate spatial data from distributed sources. The target was Australian spatial data "of national significance", meaning most - initially all - of the data considered was Australian Federal government data. Going forward, Loc-I is not limited to this sort of data, so other government data (States, Local) as well as non-government data may be included.
See the project website, http://www.ga.gov.au/locationindex, for more project information.
3.2. Loc-I Technical Implementation
The technical implementation of Loc-I was based on Semantic Web principles allowing for datasets to be published as Linked Data independently by data holders - different government departments, companies etc. - and consumed with minimal effort required for integration.
The technical implementation relied on a Loc-I Ontology, the main Loc-I model, multiple Background Models, fundamental, standards, data models that the Loc-I Ontology depended on, and, for some datasets, Dataset Models of their content that spefialise the Loc-I Ontology.
Figure 1 below shows the original detailed architecture diagram used to explain Loc-I’s parts from 2018 - 2021. This supermodel document does not detail the technical implementation of Loc-I elements but does provide a formal, integrated, model for all the elements in that figure. The OWL ontology elements represented on the left are all included in this supermodel unchanged, however several additional background ontologies and profiles have been added to better integrate Loc-I datasets' models. These include the OGC LD API profile [OGCLDAPI] wich is used to ensure data meets, or to build out data to meet, requirements of the Open Geospatail Consortium’s OGC API - Features [OGCAPI] which is now used as the standard API for Loc-I datasets. That standard was not available when the original Loc-I project was started in 2018.
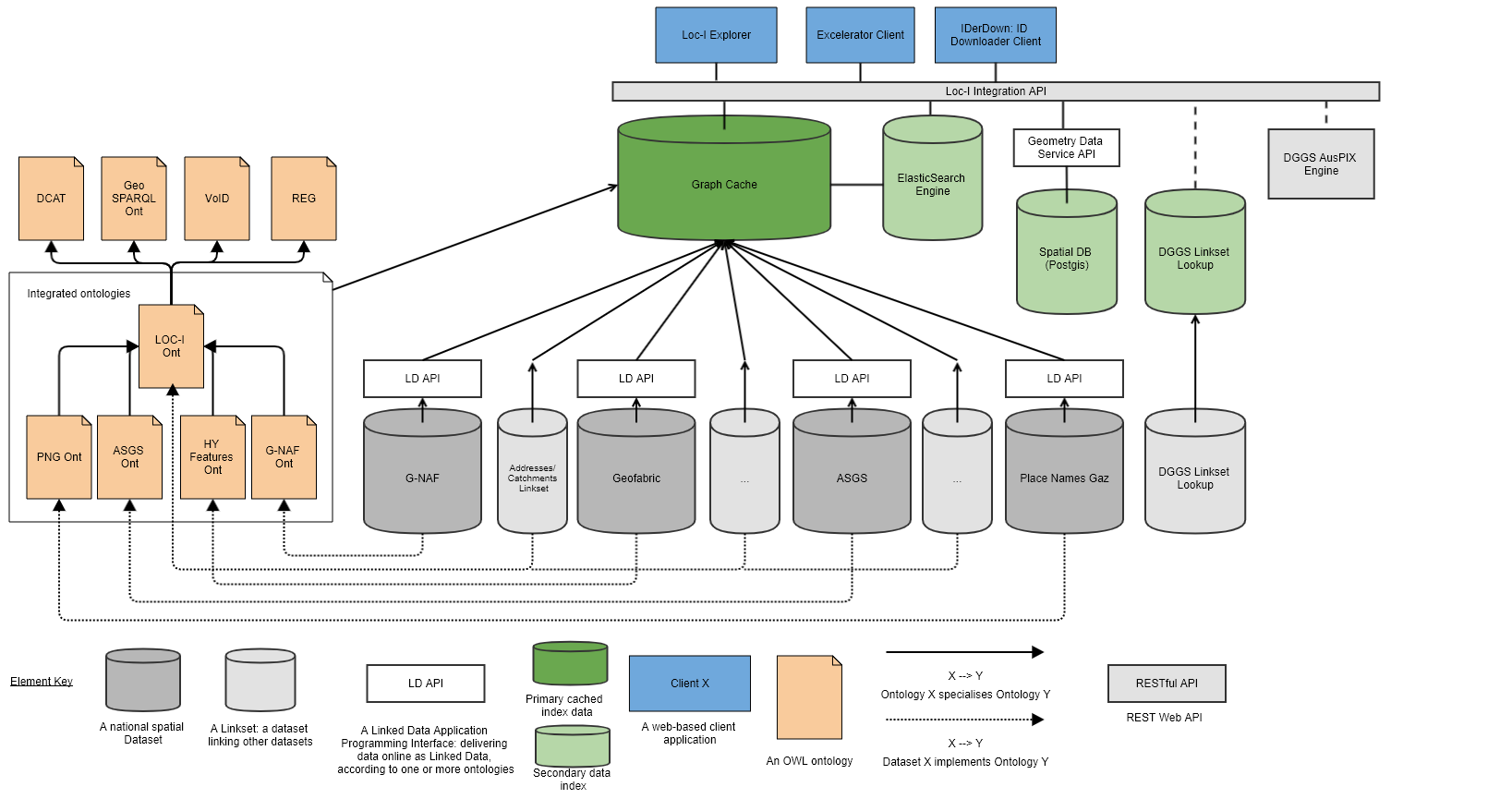
3.3. Supermodel Specification role
This Loc-I Supermodel Specification document formally defines the technical model implementation of Loc-I including all previously created models and relations as well as new models that have been added since the original Loc-I project, for example data models for new Loc-I datasets.
4. Model
The model that this Supermodel is based on is a small Semantic Web Ontology that defines the major model elements and other terminology used.
In this Specification, this implementation of the Supermodel model is presented via a series of "Levels" which are progressively more detailed, domain-specific, views of the model.
4.1. Level 0: Model Background
This view of the model is a backgrounding one which describes the underpinning model mecahnics that it uses. The object modelling used is based on the Web Ontology Language [OWL] and its own underlying use of RDF & RDFS [1]. The Provenance Ontology [PROV] is used to model real-world causal dependencies - provenance.
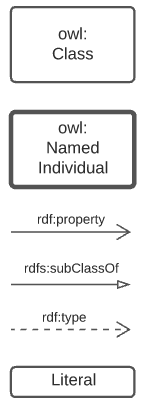
4.1.1. Diagram Key
The figure below is a key for the elements in all of the model diagrams in this document.
4.1.2. Object Modelling
The elements from the above subsection are shown in relation to one another in the figure below.
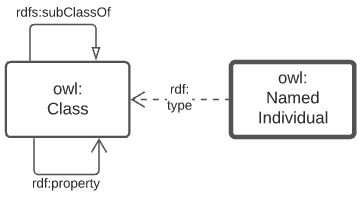
The elements shown above are identified with prefixed IRIs that correspond to entries in the Namespace Table. A short explanation of the diagram key elements is:
-
owl:Class- represents any conceptual class of objects. Classes are expected to contain individuals - instances of the class - and the class, as a whole, may have realtions to other classes -
owl:NamedIndividual- an individual of anowl:class. For example, for the class ships, an individual might be Titanic -
rdf:property- a relationship between classes, individuals, or any objects and Literals -
rdfs:subClassOf- anrdf:propertyindicating that the domain (from object) is a subclass of the range (to objects). An example is the class student which is a subclass of person: all students are clearly persons but not vice versa -
rdf:type- the property that related anowl:NamedIndividualto theowl:Classthat it’s a member of -
Literal- a simple literal data property, e.g. the string "Nicholas", or the number 42. Specific literal types are usually indicated when used
4.1.3. Provenance
General provenance/lineage information about anything - a rock sample, a dataset, a term in a vocabulary etc. - is described using the Provenance Ontology [PROV] which views everything in the world as being of one or more types in Figure 3.
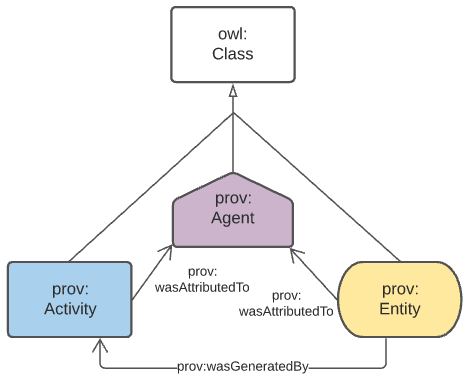
According to PROV, all things are either a:
-
prov:Entity- a physical, digital, conceptual, or other kind of thing with some fixed aspects -
prov:Agent- something that bears some form of responsibility for an activity taking place, for the existence of an entity, or for another agent’s activity -
prov:Activity- something that occurs over a period of time and acts upon or with entities
While not often in front of mind for objects in any Data Domain, provenance relations always apply, for example: a sosa:Sample within the Sampling domain is a prov:Entity and will necissarily have been created via a sosa:Sampling which is a prov:Activity. Another example: an sdo:Person related to a dcat:Dataset via the property dcterms:creator in the DataCataloging domain is a specialised form of a prov:Agent related to a prov:Entity via prov:wasAttributedTo.
4.2. Level 1: Data Domains
The top-level view of the GA supermodel that assumes Level 0 background mechanics shows a set of 5 Data Domains which are:
These are shown in Figure 1 below.
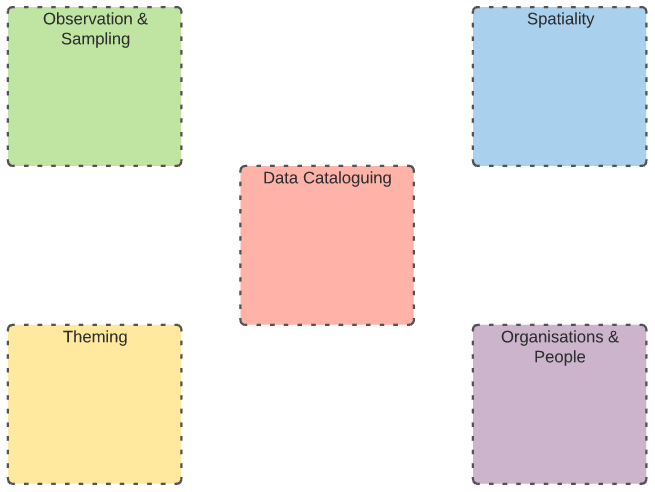
These Data Domains are defined formally in a simple SKOS vocabulary within this model’s set of machine-readable resources. The vocabulary may be access ddirectly at https://linked.data.gov.au/def/supermodel/data-domains.
Elements at all other levels of detail in this model are classified according to these Data Domains by use of the dcat:theme property, for example, the class sosa:Sample is within the Sampling Data Domain, so it is defined as follows:
sosa:Sample
a owl:Class ;
dcat:theme super:sampling ;
...
.4.3. Level 2: Central Classes
The next level of detail after the Data Domains introduces the Central Classes. Here the most significant, general, class per Data Domain is indicated, along with the main relationships between each of them. Figure 2 shows this.
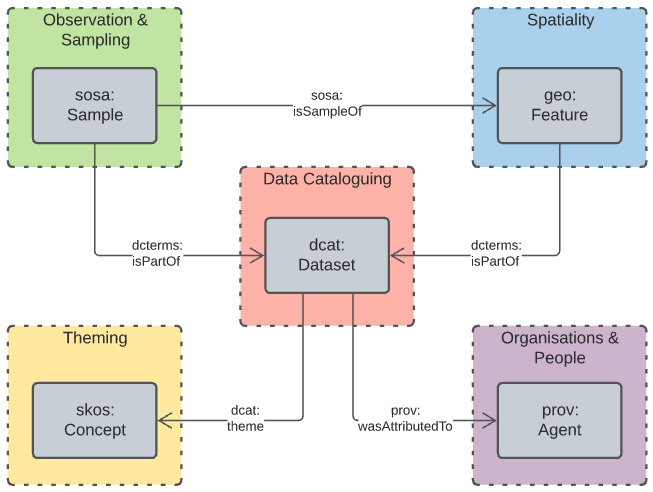
The Central Classes of each of the Data Domains are well-used classes from well-known models. For example, the Central Class of Organisation & People is [PROV]'s Agent class which is one of the three main classes of thing in PROV and used every time PROV is used to represent causal agents. PROV is used extensively to indicate how things - data, resources, systems - come to be.
A list of the Data Domains' Central Classes, their definitions, as given by their defining systems, and their defining system are given in Table 2 below.
| Data Domain | Central Class | Definition | Defined By |
|---|---|---|---|
Data Cataloguing |
|
A collection of data that is listed in the catalog. |
Data Catalog Vocabulary [DCAT] |
Organisations & People |
|
An agent is something that bears some form of responsibility for an activity taking place, for the existence of an entity, or for another agent’s activity |
PROV-O: The PROV Ontology [PROV] |
Theming |
|
An idea or notion; a unit of thought |
Simple Knowledge Organization System ontology [SKOS] |
Observation & Sampling |
|
A Sample is the result from an act of Sampling. Feature which is intended to be representative of a FeatureOfInterest on which Observations may be made. Physical samples are sometimes known as 'specimens'. |
Sensor, Observation, Sample, and Actuator Ontology, within [SSN] |
Spatial |
|
A discrete spatial phenomenon in a universe of discourse |
GeoSPARQL Ontology [GEO] |
The definitions of the main relations between Central Classes are given in
| Central Class | Definition | Defined By |
|---|---|---|
|
A collection of data that is listed in the catalog. |
Data Catalog Vocabulary [DCAT] |
|
A Sample is the result from an act of Sampling. Feature which is intended to be representative of a FeatureOfInterest on which Observations may be made. Physical samples are sometimes known as 'specimens'. |
Sensor, Observation, Sample, and Actuator Ontology, within [SSN] |
|
A discrete spatial phenomenon in a universe of discourse |
GeoSPARQL Ontology [GEO] |
|
An idea or notion; a unit of thought |
Simple Knowledge Organization System ontology [SKOS] |
|
An agent is something that bears some form of responsibility for an activity taking place, for the existence of an entity, or for another agent’s activity |
PROV-O: The PROV Ontology [PROV] |
4.4. Level 3: Domain Main Classes
At this level, the main classes within each Data Domain are identified and related to one another. In each Data Domain there is a well-known model used for the majority of the classes and relations. These well-known models are indicated to ensure that they can be followed if extensions to this level’s modelling need to be made.
4.4.1. Data Cataloguing
This subsection details the main elements of the Data Cataloguing Data Domain.
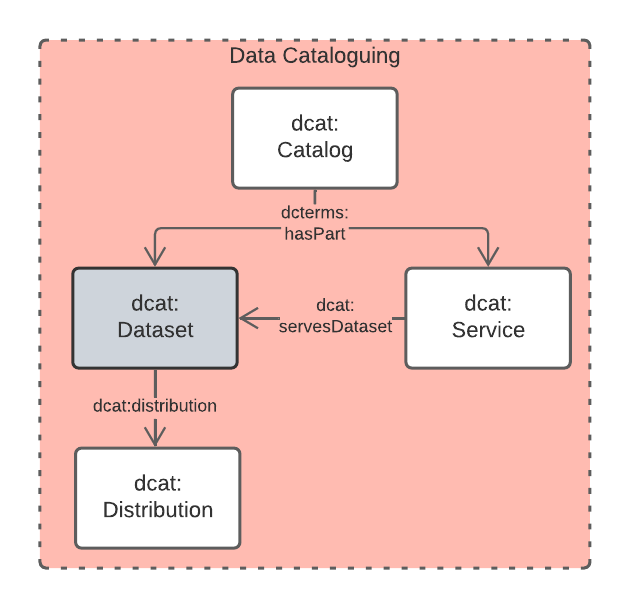
This Data Domain’s main classes are essentially the DCAT2 data model [DCAT] with a slight profiling: dcterms:hasPart should be used to indicate elements within catalogues (e.g. dcat:Dataset and other things within a dcat:Catalog) rather than the specialised properties of dcat:dataset because generic catalogue can be expected to catalogue many types of things and the type of the thing should be given by the thing, not the catalogue property used to indicate it.
4.4.2. Organisations & People
This subsection details the main elements of the Organisations & People Data Domain.
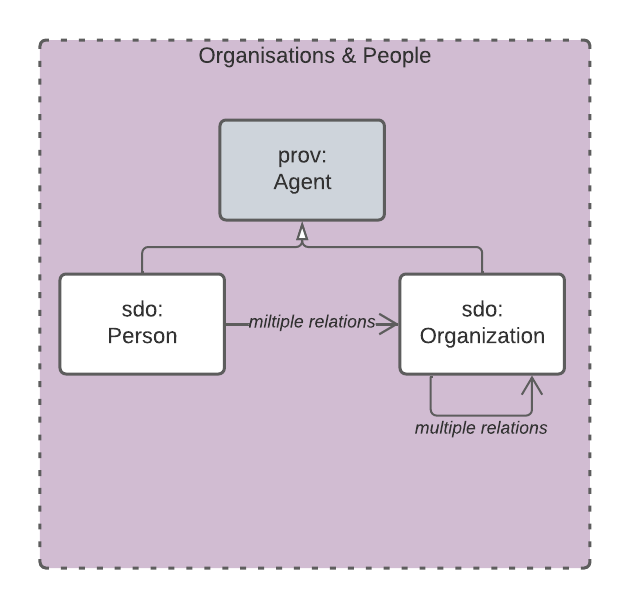
4.4.3. Theming
This subsection details the main elements of the Theming Data Domain.
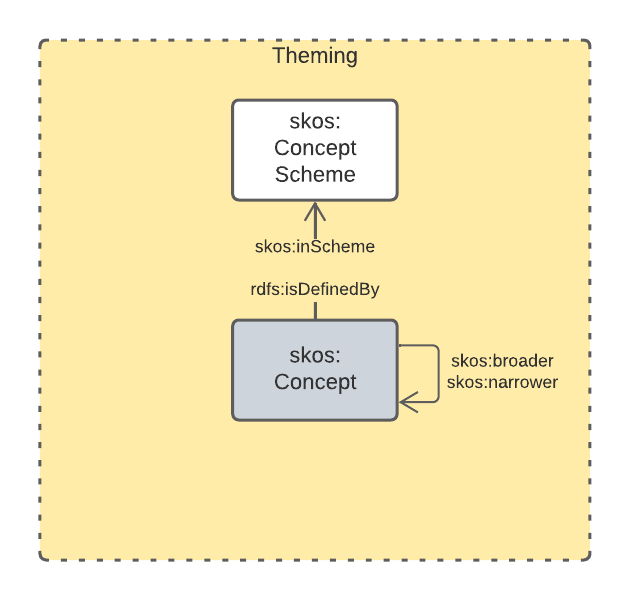
This Data Domain’s main classes are taken from [SKOS] and their expected/required properties and relations are formally defined in VocPub, a "vocabulary publication profile of SKOS" [VOCPUB]. VocPub just mandates certain vocabulary metadata and relations between elements in vocabularies. Conformance of vocabularies to VocPub is also easily testable using the profile’s validator and online tooling that support it [3].
4.4.4. Sampling & Observation
4.4.5. Spatial
This subsection details the main elements of the Spatial Data Domain.
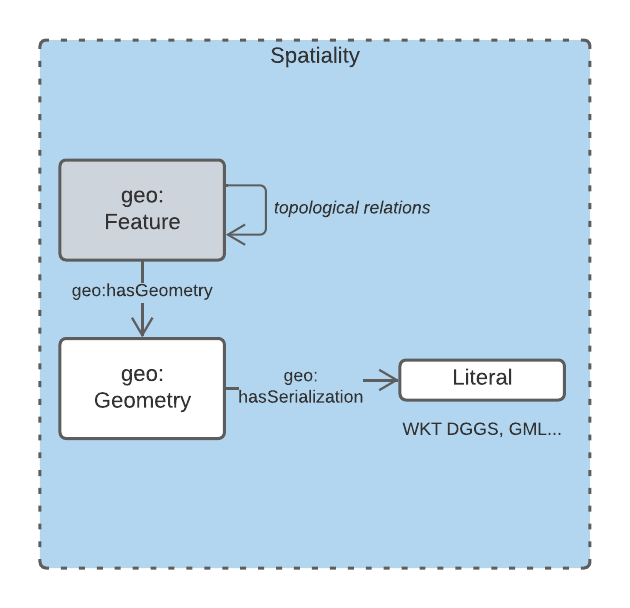
This Data Domain’s main classes are taken directly from GeoSPARQL 1.1 [GEO] which is used extensively for Semantic Web spatial data already. GeoSPARQL’s main purposes are to relate things (geo:Feature) to their spatial projections - their geometries - and to relate things to one another - topological relations between features, such as within, touches, disjoint etc.
Particular datasets tend to implement specialised types of things (usually referred to as Feature Types) and sometimes specialised relations between things, e.g. special hydrological catchment feature type might relate to another by being upstream of it. This is as per modelling in the Geofabric [4].
5. Data Domain Details
The Data Domains described above are implemented using multiple models and other resources. The following subsections describe the Domains' details and link to all their resources.
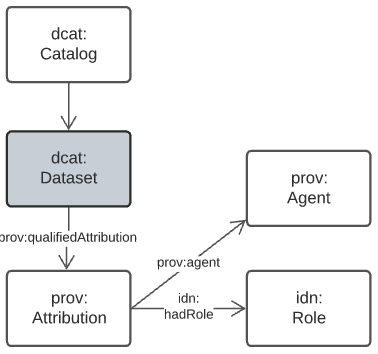
5.1. Data Cataloguing Domain
This model is based on the Data Catalog Vocabulary [DCAT] and The Provenance Ontology [PROV] with extensions to cater for mappings to FAIR [FAIR] and CARE [CARE] models. The essential model is shown in Figure 8.
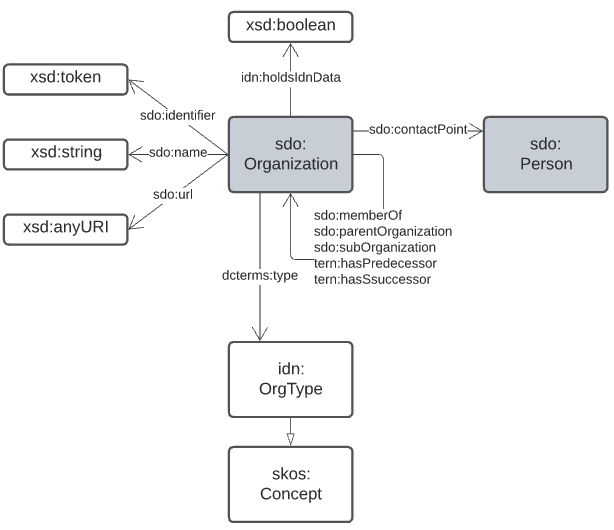
5.2. Organisations & People Domain
This domain is essentially the organization modelling element of schema.org with a few additional properties to track some aspects of organisations relevant to data governance. The essential model is shown in Figure 10.
5.3. Theming Domain
still to come
5.4. Sampling & Observations Domain
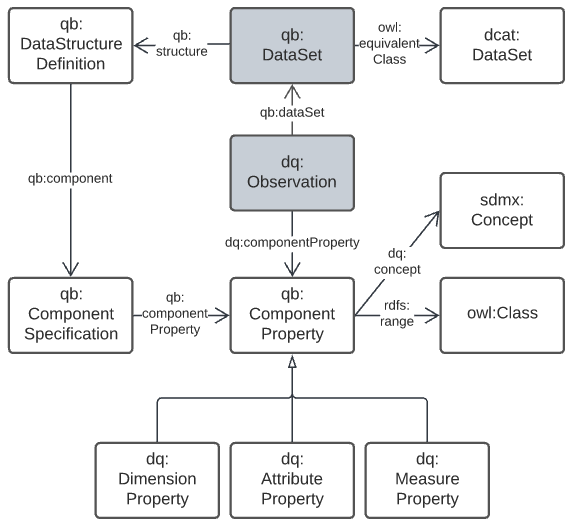
This domain is essentially the Data Cube Vocabulary [DQ]'s core elements with dataset metadata replaced with elements from DCAT [DCAT]. The essential model is shown in Figure 9.
5.5. Spatiality Domain
The Spatiality domain is the promary concern of the Loc-I Project since the project aims to provide an integration mthdology, models and an integrated and estensible "spine" of major national spatial datasets.
References
-
Department of Agriculture, Water and the Enviroment, Australia Biodiversity Information Standard (ABIS), Australian government Semantic Web Standard (2022-01-14). https://linked.data.gov.au/def/abis
-
DCMI Usage Board, DCMI Metadata Terms, A DCMI Recommendation (2020-01-20). https://www.dublincore.org/specifications/dublin-core/dcmi-terms/
-
World Wide Web Consortium, Data Catalog Vocabulary (DCAT) - Version 2, W3C Working Group Note (04 February 2020). https://www.w3.org/TR/vocab-dcat/
-
Open Geospatial Consortium, OGC GeoSPARQL - A Geographic Query Language for RDF Data, Version 1.1 (2021). OGC Implementation Specification. http://www.opengis.net/doc/IS/geosparql/1.1
-
International Organization for Standardization, ISO 19156: Geographic information — Observations and measurements (2011)
-
Open Geospatial Consortium, _OGC API - Features, overview website (2022). OGC Implementation Specification. https://ogcapi.ogc.org/features/. Accessed 2022-03-03
-
SURROUND Australia Pty Ltd, OGC LDA PI Profile, Profiles Vocabulary Profile (2021). https://w3id.org/profile/ogcldapi
-
World Wide Web Consortium, OWL 2 Web Ontology Language Document Overview (Second Edition), W3C Recommendation (11 December 2012). https://www.w3.org/TR/owl2-overview/
-
World Wide Web Consortium, The Profiles Vocabulary, W3C Working Group Note (18 December 2019). https://www.w3.org/TR/dx-prof/
-
World Wide Web Consortium, PROV-O: The PROV Ontology, W3C Working Group Note (18 December 2019). https://www.w3.org/TR/prov-o/
-
W3C Schema.org Community Group, schema.org. Community ontology (2015). https://schema.org
-
World Wide Web Consortium, Semantic Sensor Network Ontology, W3C Recommendation (19 October 2017). https://www.w3.org/TR/vocab-ssn/
-
World Wide Web Consortium, SKOS Simple Knowledge Organization System Reference, W3C Recommendation (18 August 2009). https://www.w3.org/TR/skos-reference/
-
World Wide Web Consortium, RDF 1.1 Turtle Terse RDF Triple Language, W3C Recommendation (25 February 2014). https://www.w3.org/TR/turtle/
-
SURROUND Australia Pty Ltd, VocPub, Profile of SKOS (14 June 2020). https://w3id.org/profile/vocpub